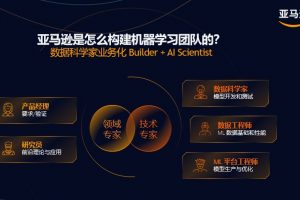
6 月 7 日,腾讯混元团队联合中山大学、香港科技大学,联合推出全新图生视频模型“Follow-Your-Pose-v2”,只需要输入一张人物图片和一段动作视频,就可以让图片上的人跟随视频上的动作动起来,生成视频长度可达 10 秒。

与此前推出的模型相比,“Follow-Your-Pose-v2”可以在推理耗时更少的情况下,支持多人视频动作生成。此外,模型具备较强的泛化能力,无论输入的人物图片的人物是什么年龄、服装、人种,人物图片的背景多么杂乱,动作视频的动作有多么复杂,都能生成出高质量的视频。

对于使用者来说,“Follow-Your-Pose-v2”让使用者可以用任意一张人物图片和一段动作视频即可生成高质量的视频,不再需要费力寻找满足高要求的图片和视频,这些照片可以是自己和家人朋友的生活照,也可以使用是偶像的一张简单的抓拍。

在动作驱动图片生成视频的任务中,一般的方法往往需要精心筛选高质量训练数据,成本高的同时还限制了训练集的规模,从而导致模型在泛化能力的提升上有瓶颈。同时,模型对于图片上蕴含的空间信息的理解能力有限,具体表现在前景和后景的区分不清晰,导致生成视频背景的畸变和人物动作的不准确。
为了解决这些问题,“Follow-Your-Pose-v2”提出了一个支持任意数量的 “指导器”的框架,通过引入额外信息来赋予模型额外的能力。其中,该框架中特有的“光流指导器”引入了背景光流信息,赋予了模型在大量有噪声的低质量数据上训练收敛的能力;该框架中特有的“推理图指导器”引入了图片中的人物空间信息,赋予模型更强的动作跟随能力。
最值得一提的是,“Follow-Your-Pose-v2”还支持单张图片上多个人物的动作驱动。模型特有的“深度图指导器”引入了多人物的深度图信息,增强了模型对于多角色的空间位置关系的理解和生成能力。在面对单张图片上多个人物的躯体相互遮挡问题,“Follow-Your-Pose-v2”能生成出具有正确的前后关系的遮挡画面,保证多人“合舞”顺利完成。

图像到视频生成的技术在电影内容制作、增强现实、游戏制作以及广告等多个行业的AIGC应用上有着广泛前景,是2024年最热门的AI技术之一。
腾讯混元大模型团队正在持续研究和探索多模态技术,拥有行业领先的视频生成能力。此前,腾讯混元大模型作为技术合作伙伴,支持多家媒体机构制作高质量的主题宣传视频,展示出了较强的内容理解、逻辑推理和画面生成能力。
本研究目前相关技术论文已上传公共社区,论文链接:https://arxiv.org/abs/2406.03035