7月26日,智谱AI CEO张鹏在智谱 Open Day上宣布,AI生成视频模型清影(Ying)正式上线智谱清言,生成6秒视频只需要30秒的时间。即日起所有C端用户,都能通过清影(Ying)体验到AI文生视频、图生视频能力。
智谱AI CEO 张鹏表示。Sora 带来AI大模型的全新玩法,大模型可基于任意文字生成视频,这也是这个“大家庭”若干努力(包括Runway的Gen系列、微软的Nuwa、Meta的Emu、谷歌的Phenaki/VideoPoet、CogVideo等)的一个全新高度。今天,这个大家庭迎来一个新伙伴清影(Ying)。
只要你有好的创意(几个字到几百个字),再加上一点点耐心(30秒),清影(Ying)就能生成6 秒时长,1440x960清晰度,3:2 比例。
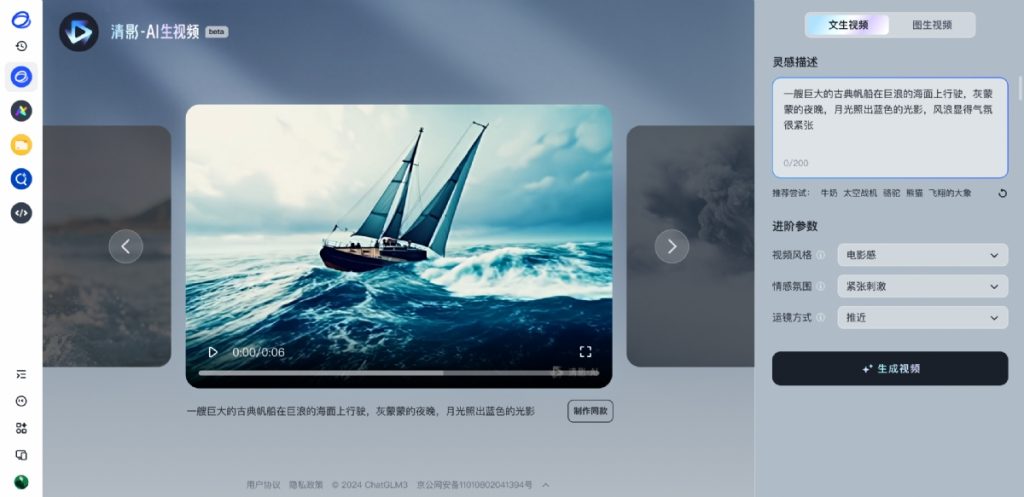
即日起,清影(Ying)上线清言App,面向所有用户开放。用户输入一段文字(Prompt),可以选择自己想要生成的风格,包括卡通3D、黑白老照片、油画、电影感等,就可拥有自己的一段AI视频。让脑中的灵感变成现实。除了文字到视频,大家也可以到清影上玩图生视频。简单来说,上传一个图片,AI就能让凝练在时光中的照片动起来。
张鹏表示,这次生成式视频能力的全面上线,为的是让大家都能体验生成式视频功能,希望能够听到大家的意见和反馈。未来,智谱 AI 将采用快速迭代的方式,不断提升生成式视频模型能力。Scaling Law持续探索,智谱AI阶段性成果汇报在生成式视频模型的研发中,Scaling Law 继续在算法和数据两方面发挥作用。
“我们积极在模型层面探索更高效的scaling方式。”张鹏表示:“随着算法、数据不断迭代,相信Scaling Law将继续发挥强大威力。”本次清影(Ying)底座的视频生成模型是CogVideoX,它能将文本、时间、空间三个维度融合起来,参考了Sora的算法设计,它也是一个DiT架构,通过优化,CogVideoX 相比前代(CogVideo)推理速度提升了6倍。理论上,模型侧生成6秒视频仅需30秒时间。
智谱自研了一个端到端视频理解模型,用于为海量的视频数据生成详细的、贴合内容的描述,这样可以增强模型的文本理解和指令遵循能力,使得生成的视频更符合用户的输入,能够理解超长复杂prompt指令。在内容连贯性上,智谱AI自研高效三维变分自编码器结构(3D VAE),将原视频空间压缩至2%大小,配合3D RoPE位置编码模块,更有利于在时间维度上捕捉帧间关系,建立起视频中的长程依赖。CogVideoX 模型亦同步上线智谱AI大模型开放平台 bigmodel.cn,开发者可以通过调用API的方式,体验和使用文生视频以及图生视频的模型能力,在国内尚属首次。
据了解,智谱 AI 生成式视频研发得到北京市的大力支持。当前,北京正在以海淀区为核心打造人工智能产业高地,海淀区是智谱AI总部所在地,为智谱AI开展大模型研发提供了产业投资、算力补贴、应用场景示范、人才等全方位支持。智谱 AI 生成式视频研发算力支持来自于亦庄集群。北京亦庄着眼打造人工智能之城,目前,北京亦庄人工智能公共算力平台已建成。bilibili作为合作伙伴也参与并支持清影的研发过程。同时,合作伙伴华策影视也参与了模型共建。
人工智能行业对多模态模型的探索还处于初级的阶段,清影(Ying)还将不断迭代,智谱AI 将持续努力打造对标世界先进水平的模型产品矩阵,致力于通过大模型链接物理世界的亿级用户,为千行百业带来持续创新与变革,加速迈向通用人工智能时代。