科技云报道原创。
10年前,Pentaho公司创始人兼CTO詹姆斯·迪克逊(James Dixon)在他的博客中第一次提出“数据湖”(Data Lake)的概念;10年后的今天,在业界“数据中台”大火的时代背景下,再来讨论“数据湖”,别有一番风味。

历史的演变:从“数据仓库”到“数据湖”
在万物互联的时代,各行各业、各类设备和应用都在24小时不间断产生大量数据。IDC统计显示,全球近90%的数据将在这几年内产生,预计到2025年,全球数据量将比2016年的16.1ZB增加十倍,达到163ZB。数据的海量与多元化决定了从数据中获取有用的价值变得越来越困难,如果无法从数据中获得益处,那么数据价值就无从谈起。
这时候,数据需要更深度的价值挖掘。目前,数据的价值呈现两极化特征,一是及时发现,实时分析快速促进业务发展;二是长期存放,数据累积起来,探索数据后隐藏的规律,统一分析其价值,为业务发展提供参考。
新的数据价值给企业带来更多智能创新应用,比如增长黑客、推荐系统,用户行为分析,AIoT带来的更多模型,这也意味着IT基础设施的变革。
以往的计算和存储耦合的架构就会呈现资源利用率非常低的状况,数据是不断累积、不断增长,但计算的算力要求可能是峰谷,为了存储更多的数据购买更多的计算,扩容的时候必须一起扩容,最终导致稳定性不是最优,两种资源无法独立扩展,使用成本也不是最优。
在传统架构中,原始数据统一存放在Hadoop分布式文件系统(HDFS)系统上,引擎以Hadoop和Spark 为主,受到开源软件本身能力的限制,传统技术无法满足企业用户在数据规模、存储成本、查询性能以及弹性计算架构升级等方面的需求。
如果这些多元的数据无法被其它应用所使用,那么这一过程不可避免地会形成数据孤岛,以至于无法满足数据量迅速增长的需求。
传统数据处理方式,就像“一条小河”,里面有ERP、CRM等各种业务系统,用户可以设计“一个河道”,数据库在最底层。数据经过整理后形成中间层的数据仓库,然后通过商务智能工具(BI)来及进行展示。
简单理解,在传统数据处理过程中,用户大概知道能有多少“水”,还可以通过“闸门”管控水量。
但是,在互联网时代,各种各样的视频、移动终端信息如“洪水猛兽”,形成大规模的海量数据,用户来不及整理和使用。这时,一个新的设想打开了人们的视野,假设有那么一片洼地,没有河道,所有数据先蓄积到里面,然后通过有效的工具进行查询和处理,这便是数据湖。
国际研究机构MarketsandMarkets最新研究报告显示,到2024年,全球数据湖市场将突破200亿美元,增至201亿美元,复合年增长率将高达20.6%。可以说,随着数据治理与应用需求激增,数据湖成为数据管理的重要方式已成为不争的事实。
对于数据湖而言,有几个重要特点。第一,存储的原始自然数据,既可以是结构化数据,也可以是非结构化数据;第二,因为使用了云计算,用户可以快速缩放海量数据;第三,在数据查询过程中,除了能进行建目录、数据迁移和抽取等动作,还能进一步归类、进行数据分析等等。另外,数据湖不仅是高可用、高持久、海量数据处理的选择,同时还能满足安全、合规和审计等要求。

而对于用户来说,借助最新的数据湖解决方案,不仅能解决过去的数据孤岛问题,同时还能兼容传统的数据仓库和数据分析方法。最重要的是,更适合现代应用部署,比如和机器学习结合,进行预测性的分析。
数据湖与数据仓库并不是替代关系 湖仓一体化成为新趋势
随着数据湖概念的兴起,业界对于数据仓库和数据湖的对比甚至争论就一直不断。有人说数据湖是下一代大数据平台,各大云厂商也在纷纷的提出自己的数据湖解决方案,一些云数仓产品也增加了和数据湖联动的特性。不过在我们看来,数据湖与数据仓库并不是替代关系,而是互为补充、相辅相成。
无论是数据仓库,还是数据湖,其所要解决的问题离不开数据的存储、调用、处理、分析、应用等。而随着需求侧的发展变化,数据湖与数据仓库被寄予了更高的期待:如何完成内部的统一,从而满足数据访问使用的灵活性与高性能并举。
早期业界认为数据湖可能将会是未来的主流趋势,甚至有数据湖代替数据仓库之势,但随着新技术发展的热度下降,市场对数据湖的认知愈发理性。毕竟,数据仓库在决策支持和商业智能应用方面有着悠久的历史。
也因此,湖仓一体化(Lakehouse)正在成为近些年来的热点。湖仓一体采用开放式架构,既构建于数据湖低成本的数据存储架构上,同时具备数据仓库的数据处理和管理功能,助力商业决策。因此,从某种程度上来讲,数据湖产品的不断迭代升级也是在向湖仓一体化趋势靠近。随着企业及组织不断上云、数据分析需求的激增,湖仓一体化分析方案正在成为下一代数据分析系统的核心。
如今,越来越多的企业开始融合数据湖和数据仓库的平台,不仅可以实现数据仓库的功能,还实现了各种不同类型数据的处理功能、数据科学、用于发现新模型的高级功能。
相比单独的数据仓库和数据湖,湖仓一体提供完善的数据管理能力。数据湖中会存在两类数据:原始数据和处理后的数据。数据湖中的数据会不断的积累、演化,包含数据源、数据连接、数据格式、数据schema,对于数据具有一定的权限管理能力。
其次,湖仓一体为企业提供全量数据的存储场所,可以对数据的全生命周期进行管理,包括数据的定义、接入、存储、处理、分析、应用的全过程。一个强大的数据湖,需要能做到对其间的任意一条数据的接入、存储、处理、消费过程是可追溯的,能够清楚的重现数据完整的产生过程和流动过程。
一般情况下,数据的加载、转换、处理会使用批处理计算引擎;需要实时计算的部分,会使用流式计算引擎;对于一些探索式的分析场景,可能又需要引入交互式分析引擎。对此,湖仓一体拥有丰富的计算引擎,提供从批处理、流式计算、交互式分析到机器学习等各类计算引擎。
湖仓一体本身还内置多模态的存储引擎,以满足不同的应用对于数据访问需求。但是,在实际的使用过程中,为了达到可接受的性价比,湖仓一体解决方案提供可插拔式存储框架,支持的类型有HDFS/S3等, 并且在必要时还可以与外置存储引擎协同工作,满足多样化的应用需求。
作为全球云计算巨头,亚马逊云科技在数据仓库方面已经拥有多款产品,比如:Amazon Redshift,是一个基于云的重要的数据仓库产品,不仅具有强大的缩放能力,成本也是传统的数据库的十分之一。还有图形数据库Amazon Neptune,也在中国成功落地。
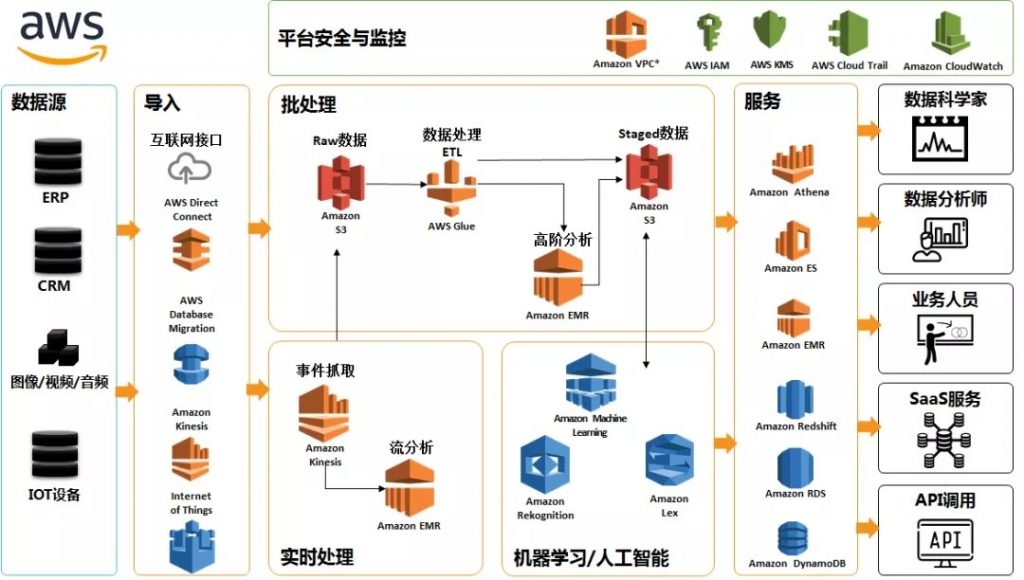
近期,亚马逊云科技又针对数据及数据分析等服务持续发力,推出“智能湖仓”架构。据了解,“智能湖仓”架构将亚马逊云科技的数据服务无缝集成,打通数据湖和数据仓库之间数据移动和访问,并且进一步实现数据在数据湖、数据仓库,以及在数据查询、数据分析、机器学习等各类专门构建的服务之间按需移动,从而形成统一且连续的整体,满足客户各种实际业务场景下的不同需求。
“智能湖仓”架构以Amazon Simple Storage Service(Amazon S3)为基础构建数据湖,作为中央存储库,围绕数据湖集成专门的“数据服务环”,包括数据仓库、机器学习、大数据处理、日志分析等数据服务,然后再利用Amazon Lake Formation、Amazon Glue、Amazon Athena、Amazon Redshift Spectrum等工具,实现数据湖的构建、数据的移动和管理等。
从Linux基金会开启开源Lakehouse项目、Databricks新添Delta Engine来增强Lakehouse服务能力,到Apache Iceberg的火热、AWS Lake Formation等,不难看到,湖仓一体化正在成为主流服务商们探索的方向。同时,随着国内外厂商们纷纷加入开源生态,推动生态不断成熟,数据湖与数据仓的关联正在变得愈发密切。
不管是大数据开发者,还是企业大数据技术决策者,都应该重新审视数据湖和数据仓库的融合应用,通过构建更强大的业务平台为企业减轻运营压力,提高工作效率,让企业IT为业务创造更多新的可能。
【关于科技云报道】
专注于原创的企业级内容行家——科技云报道。成立于2015年,是前沿企业级IT领域Top10媒体。获工信部权威认可,可信云、全球云计算大会官方指定传播媒体之一。深入原创报道云计算、大数据、人工智能、区块链等领域。





