科技云报道原创。
在哈利·波特的魔法世界中,分院帽是一顶磨得很旧,打着补丁,而且脏得要命的尖顶巫师。不过可别小看它,它可是充满智能、会思想的魔法帽,能看出学生具备何种才能,从而将学生分到适合的学院。

如果现实世界存在分院帽的话,那么它应该类似于机器学习的应用程序,可以根据复杂的数据集自主地做出决策。
如今,机器学习正在推动数万亿规模的全球产业,市场调查机构Grand View Research最近发布的《机器学习市场报告2025》预计,到2025年,全球机器学习市场规模将达到967亿美元。2019年-2025年的年复合增长率为43.8%,其中金融服务,零售和汽车领域处于领先地位。如果机器学习有望创造更大规模的市场价值,那么问题来了:这些价值将在哪里产生呢?

从初创公司到科技巨头 机器学习深度嵌入垂直场景
早在50年前,机器学习的概念就出现了。只是直到今天,随着云计算的出现,人工智能和机器学习才进入千千万万的企业,不再局限于少数科技巨头和硬核的研究机构。云计算时代的到来,扫清了企业应用人工智能和机器学习的障碍,而即便最保守的企业在当今都无法忽视人工智能的作用。根据IDC的数据,当前40%的企业数字化转型项目都会运用人工智能。
Facebook、Amazon、Apple、Netflix、Google等科技巨头在机器学习方面的创新广为人知,从新闻推送到推荐引擎不一而足。其实,这些科技巨头在机器学习领域早已布局。比如Amazon就在这个领域已经投入了20多年,其在线零售的个性化产品推荐、机器人仓储中心、无人机送货、Alexa语音助理、Amazon GO无人值守超市,都依靠人工智能和机器学习技术的支持。
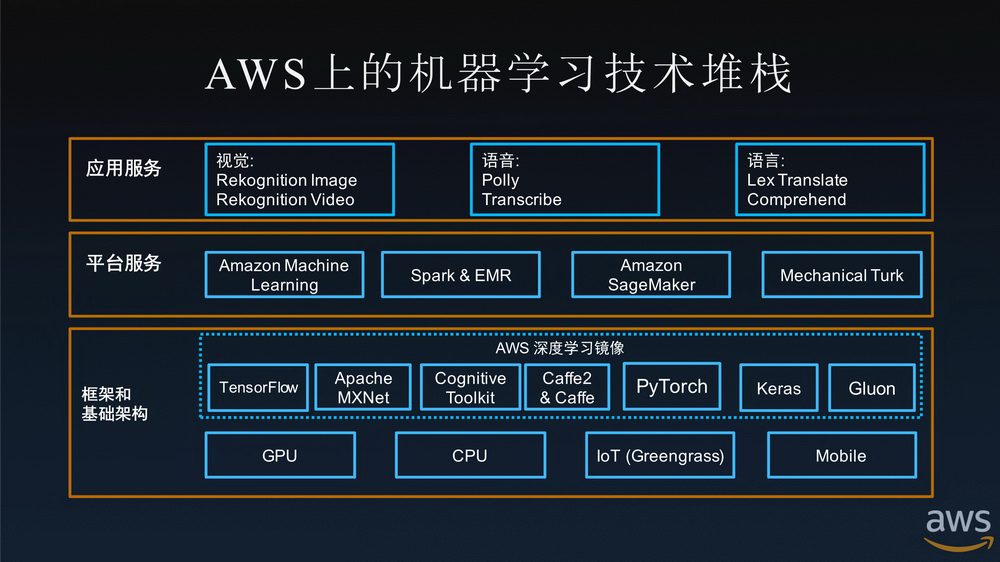
但就更多场景而言,人工智能的应用仍然较为局限。目前,制约人工智能广泛应用的因素有三个方面:一是掌握人工智能专业知识的人才不足;二是构建和扩展人工智能的技术产品有难度;三是在生产经营中部署人工智能应用费时且成本高。最终导致缺乏低成本、易使用、可扩展的人工智能产品和服务。就机器学习而言,多数机器学习方法的性能在很大程度上依赖于过量的模型设计策略,这导致新手难以较快地掌握和应用机器学习。
对此,Amazon SageMaker的出现帮助企业解决了这些挑战。作为一个工具集,Amazon SageMaker提供了用于机器学习的所有组件,比如弹性笔记本、实验管理、自动模型创建、调试与分析,以及模型概念漂移检测等多元化工具和功能,贯穿整个机器学习的工作流程,从而以更少的努力、更低的成本、更快地将机器学习模型投入生产。
2021年5月11日,Amazon SageMaker以落地中国区域一周年为契机,进一步在中国区域落地多项人工智能与机器学习的新服务和功能,“希望通过将更多服务落地到中国区域,并坚持‘授人以鱼不如授人以渔’,甚至更进一步‘扶上马,送一程’的方式,帮助客户更快应用机器学习技术,把机器学习的能力交到每一位构建者手中,加速人工智能和机器学习的普惠。”亚马逊云科技大中华区云服务产品管理总经理顾凡表示。

亚马逊云科技大中华区云服务产品管理总经理顾凡
除了科技巨头,全球一些初创型的公司也都在将机器学习与垂直领域相结合,最好的机器学习公司都有着清晰的垂直重点。他们甚至不会将自己定义为机器学习公司。比如在工业和物流领域,Covariant是一家结合了强化学习和神经网络的初创公司,该公司让机器人能够管理大型仓库设施中的物体;Interos应用机器学习技术评估全球供应链网络,帮助企业围绕供应商管理、业务连续性和风险做出关键决策。
在医疗领域,Athelas已将机器学习应用于免疫监测,通过收集病人白血球数量的数据帮助他们优化药物摄入。Curai利用机器学习技术来提高医生推荐的效率和质量,让他们可以把更多的时间花在治疗患者的工作上。Zebra和AIdoc通过训练数据集来更快地确定医疗状况,从而提高了放射科医生的工作能力。
然而,大规模部署机器学习模型也可能为企业带来诸多挑战。例如,规模化的部署需要实现“数据-模型-成果”这一复杂且反复的端到端工作流程。而且,企业也需要提高自身治理能力,合理应对模型部署可能带给终端客户服务的影响(如隐私问题),并着眼于数据应用的合规性和安全性,以及该模型是否能转化成为生产级模型等。

前途光明但道路曲折 机器学习模型仍面临四大挑战
据国外知名科技媒体VentureBeat报道,大约90%的机器学习模型从未投入生产。换句话说,机器学习只有10%能够真正产出对公司有用的东西。尽管大家都相信,人工智能将成为下一次科技革命的中心,但人工智能的采用和部署尚未获得长足的发展。目前来看,机器学习要想大规模应用仍然还面临比较大的挑战。
挑战一:数据获取和访问难度大
许多公司的IT系统都是高度筒仓化的,这意味着每个部门都有自己收集数据的方式、首选格式、存储位置以及安全和隐私偏好。另一方面,机器学习经常需要来自多个部门的数据,筒仓化模式增加了清理和处理这些数据的难度。但在今天这个技术飞速变革的时代,企业将需要加快步伐,在整个过程中建立起统一的数据结构。
挑战二:IT、数据科学和工程脱节
如果公司的目标是减少“数据筒仓”,就意味着各部门需要更多地相互沟通,调整各自的目标。但在许多公司中,IT部门和数据部门之间存在着根本性的分歧。IT倾向于优先考虑让事情正常运转并保持稳定,而数据专家则更喜欢进行一些尝试性创造,这就会导致一些不稳定情况发生,使双方的沟通产生困难。此外,对于数据专家来说,与IT工程师的沟通也是一道障碍,因为IT工程师有时候可能无法了解数据专家所设想的所有细节,或者可能会由于沟通错误而改变实现方式。
挑战三:重复性工作多 应用扩展较难
机器学习模型可能在小规模数据样本的环境中工作得很好,但这并不意味着它在任何地方都可以工作得很好。首先,可能没有处理更大数据集的硬件或云存储空间可供使用。此外,在规模很大时,机器学习模型的模块并不总是像规模较小时那么有效。另外,由于公司的筒仓结构,数据获取可能也比较困难,这也是在组织之间统一数据结构、鼓励不同部门之间进行交流的另一个原因。
在部署机器学习模型的漫长道路上,超过25%的企业都存在重复工作。例如,软件工程师可能会按数据专家的说法进行实现,后者可能也会自己做一些工作。这不仅浪费时间和资源,而且在遇到任何错误时就不知道应该向谁求助,这会导致额外的混乱。如果数据专家能够实现他们的模型,但对于职责如何划分、如何明确分工,他们应该与IT工程师沟通清楚,这样就可以节省时间和资源。
挑战四:不能跨语言且缺少框架支持
由于机器学习模型仍处于起步阶段,不同的语言和框架仍有相当大的差距。有些模型开始时使用的是Python语言开始,中间切换到R语言,最后用的是Julia语言。有的则相反,或者完全使用其他语言。由于每种语言都有自己独特的库和依赖项,项目很快就变得很难跟踪。此外,有些模型可能会使用Docker和Kubernetes进行容器化,并部署特定的API,其他模型则不会,这样的例子不胜枚举。为了弥补这种不足,像TFX、Mlflow和Kubeflow这样的工具出现了。但这些工具仍处于起步阶段,但到目前为止,这方面的专业人才还很少。
事实上,模仿人类的思维并不是机器学习的唯一目标,相反机器学习可以通过对大型数据集进行详尽的分析来提高人类的智能水平,就像搜索引擎能够通过组织Web来扩展人类的知识一样。机器学习还可以汇总多个数据集的信息,探索模式,并为一些问题提出新的解决方案,从而在医疗、商业、交通等多个领域为人类提供新型服务。
机器学习技术必将推动企业机构的变革,目前许多机器学习应用已经为企业机构带来了实际的业务成果。机器学习可以实现流程自动化、发现新洞察,从而帮助企业创造新产品或增强现有产品及服务,从而提供更好的客户体验。
但企业机构要想真正将机器学习应用到实际业务场景之中,还需完成全方位运营转型,具备建立和开发机器学习模型以及部署和运营整个模型的能力,从而全方位发掘机器学习的潜力。目前为止,大型企业孵化了最先进的技术,但是真正的希望存在于下一波机器学习应用程序和工具之中,将围绕机器智能将哈利·波特式的幻想转化为有形的社会价值。
【关于科技云报道】
专注于原创的企业级内容行家——科技云报道。成立于2015年,是前沿企业级IT领域Top10媒体。获工信部权威认可,可信云、全球云计算大会官方指定传播媒体之一。深入原创报道云计算、大数据、人工智能、区块链等领域。




